An overview of KET-QA
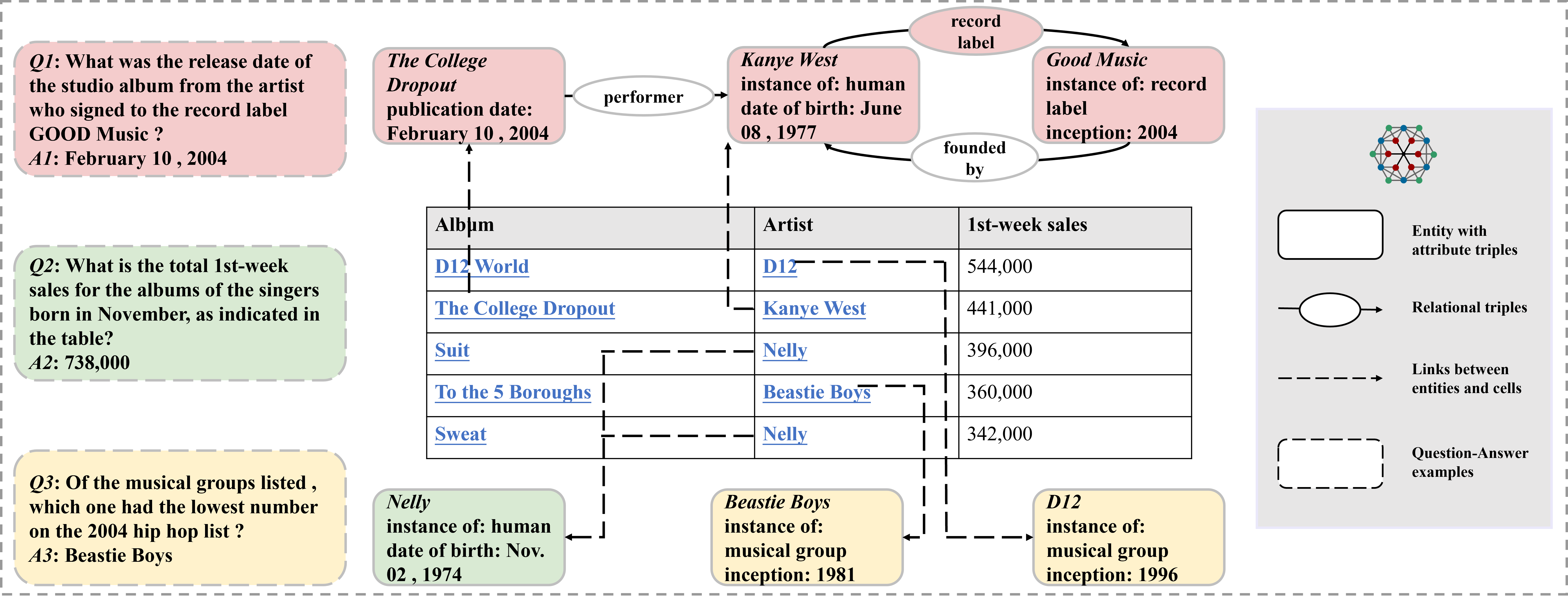
Due to the concise and structured nature of tables, the knowledge contained therein may be incomplete or missing, posing a significant challenge for table question answering (TableQA) systems. However, most existing datasets either overlook the challenge of missing knowledge in TableQA or only utilize unstructured text as supplementary information for tables.
In this paper, we propose to use a knowledge base (KB) as the external knowledge source for TableQA and construct a dataset KET-QA with fine-grained gold evidence annotation. Each table in the dataset corresponds to a sub-graph of the entire KB, and every question requires the integration of information from both the table and the sub-graph to be answered. To extract pertinent information from the vast knowledge sub-graph and apply it to TableQA, we design a retriever-reasoner structured pipeline model.
Experimental results demonstrate that our model consistently achieves remarkable relative performance improvements ranging from 1.9 to 6.5 times on EM scores across three distinct settings (fine-tuning, zero-shot, and few-shot), in comparison with solely relying on table information. However, even the best model achieves a 60.23% EM score, which still lags behind the human-level performance, highlighting the challenging nature of KET-QA for the question-answering community.